




- What Is Sample Size in A/B Testing
- Why Most A/B Tests Get Wrong Sample Size
- How to Determine the Right Sample Size for Your A/B Test
- How Traffic Impacts Your Test Duration
- Quick Decision Framework: When is Your Test Actually Ready
- How GemX Helps You Make Better A/B testing Decisions
- Common Mistakes That Lead to False Winners
- Conclusion
- FAQs about Sample Size for A/B Testing
Most A/B tests don’t fail because of bad ideas, but they fail because there isn’t enough data to trust the result.
You launch a test, see one variant “winning” after a few days, and decide to roll it out. It feels fast, efficient, and data-driven. But in reality, you might just be reacting to randomness.
If your test doesn’t have enough traffic or hasn’t run long enough, even a “20% uplift” can be misleading. And the worst part? You won’t even realize it until performance drops after deployment.
In this guide, you’ll learn how to estimate the right sample size for A/B testing, how long your test should run, and when your results are actually reliable. No complex formulas, just practical rules you can apply directly to your Shopify store.

What Is Sample Size in A/B Testing
Sample size in A/B testing refers to the number of users (or sessions) included in each variant before you evaluate the results. In a typical A/B test, your traffic is split between two versions:
-
Variant A: the original version, used as the baseline
-
Variant B: the test variation
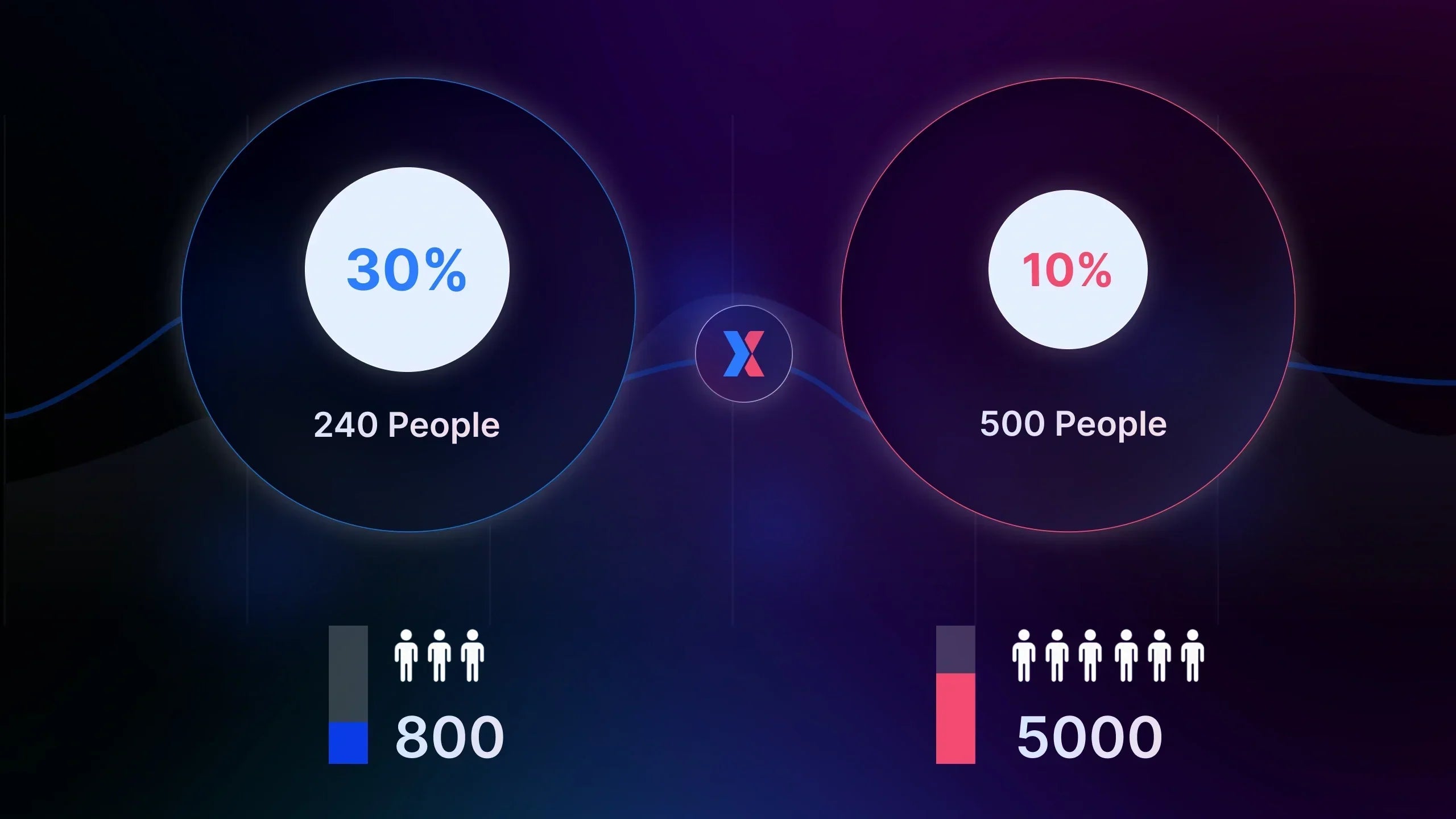
If each variant receives 5,000 visitors, then your sample size is 5,000 per variant.
In simple terms, sample size is the amount of data you collect to determine whether one version truly performs better than the other.

Furthermore, it directly impacts how much you can trust your test.
If your sample size is too small, the test results will fluctuate, which can lead you to get false winners easily. On the other hand, when it’s large enough, your test results will stabilize, and your decisions become reliable.
For example, a 15% uplift with 200 users doesn’t mean much, but the same uplift with 10,000 users is an entirely different story.
Why Most A/B Tests Get Wrong Sample Size
Most teams don’t intentionally ignore sample size, but they just underestimate how much data is actually needed to trust a result.
Here are the most common ways it goes wrong:
-
Stopping tests too early
A variant looks like it’s winning after a few days, so the test gets stopped. The problem? Early results are often unstable. What looks like a clear winner can easily reverse once more data comes in.
-
Focusing only on uplift
You see “+20% conversion rate," and it feels like a strong signal. But without enough sample size behind it, that uplift is just noise. Percentage alone means nothing without data volume to support it.
-
Testing on low-traffic pages
Running tests on pages with limited traffic slows everything down. If a page only gets a few hundred visitors per day, it can take weeks or even months to reach a meaningful sample size.
-
Splitting traffic across too many variants
The more variants you test, the less traffic each one receives. This reduces the sample size per variant and extends the time needed to reach reliable results.
How to Determine the Right Sample Size for Your A/B Test
You don’t need complex formulas to figure this out. In most cases, it comes down to understanding a few key factors, then choosing how precise you want to be.
Step 1: Understand What Impacts Your Sample Size
Two factors drive how much data you need:
1. Your baseline conversion rate (CR)
This is your starting point. If your store converts at 2%, every variation is measured against that.

Lower conversion rates make changes harder to detect, so you’ll need more users to reach a reliable result. Higher conversion rates, on the other hand, allow you to validate changes faster with less data.
2. Your minimum detectable effect (MDE)
This is the smallest uplift you actually care about.
If you’re trying to detect a small change (like +5–10%), you’ll need a larger sample size. If you’re testing bigger changes, you can reach conclusions with less traffic.
The rule is simple: the smaller the changes, the more data needed.
Step 2: Use Practical Benchmarks (Fast Estimation)
If you want a quick estimate, use this as a baseline.
|
Baseline CR |
Expected uplift |
Sample size per variant |
|
1–2% |
10–15% |
~15,000–30,000 users |
|
2–5% |
10–15% |
~5,000–15,000 users |
|
5%+ |
10–15% |
~2,000–8,000 users |
Most e-commerce A/B tests need anywhere from 5,000 to 30,000 users per variant to be reliable.
-
Low CR (1–2%): expect to need more data
-
Higher CR (5%+): can work with less
If your test has reached at least a few thousand users per variant, the result is usually stable.
Step 3: Use a Sample Size Calculator (For Precision)
When accuracy matters, a sample size calculator is your best option.
Instead of estimating, you can use tools like Optimizely’s A/B Test Sample Size Calculator or Evan Miller’s Sample Size Calculator. Both are widely used and give reliable estimates.
Most calculators work the same way. You’ll need to input:
-
Your baseline conversion rate
-
The minimum uplift you want to detect (MDE)
-
Your confidence level (typically 95%)

Example of a sample size calculation from Optimizely.
Based on these inputs, the tool will tell you how many users you need per variant to reach statistical significance. For example, if your conversion rate is 3% and you want to detect a 20% uplift, a calculator will usually estimate that you need around 13,000 users per variant.
This approach is especially useful for high-impact tests, where making the wrong decision could directly affect revenue.
Step 4: Use a Practical Rule of Thumb (No Calculation Needed)
If you don’t want to calculate every time, keep this in mind: Most reliable tests operate in the range of thousands, not hundreds, of users per variant.
As a result, in case you’re only seeing a few hundred users, even a big uplift isn’t trustworthy yet. It’s very likely just noise.
Learn more: Statistical Significance in A/B Testing: How to Know If Your Test Results Are Reliable
What If You Don’t Have Enough Traffic?
Low traffic doesn’t stop you from testing, but it changes your strategy.
You’ll need to run tests longer and focus on bigger changes that are easier to detect. It also makes more sense to prioritize high-traffic pages first, instead of spreading efforts across smaller pages.
Key takeaway: Reliable A/B testing comes with enough data. If you need a quick sanity check:
• Most tests need thousands of users per variant
• Low CR or small uplift → need more data
• Early “wins” are often misleading
• When in doubt, let the test run longer
There’s no fixed number of days for an A/B test. Your test duration depends on how quickly you can reach the required sample size.
In other words, duration is not something you decide upfront, but it’s something your traffic determines.
Estimating Your Test Duration
Once you know how much data you need, estimating duration becomes straightforward.
You’re essentially looking at how fast your traffic can fill that requirement.
A simple way to think about it:
| Test duration ≈ Required sample size ÷ Daily traffic (per variant) |
If your test needs 10,000 users per variant and each variant receives 1,000 visitors per day, it will take around 10 days to reach a reliable sample size.
This is why sample size and duration are always connected. You’re not choosing how long to run a test, but you’re waiting until enough data is collected.
Learn more: How Long Should You Run an A/B Test: Recommended Duration for Each Experiment Type
Hitting the Sample Size Is Not Enough
Reaching your sample size is necessary, but it doesn’t always mean your test is ready to stop.
User behavior isn’t consistent day to day. Traffic patterns change depending on weekdays, weekends, campaigns, and traffic sources. If your test only runs for a few days, your data may reflect short-term patterns rather than real performance.
That’s why most A/B tests should run for at least 7 to 14 days, even if the sample size is reached earlier. This ensures your results cover a full business cycle and aren’t biased by timing.
How Traffic Impacts Your Test Duration
At this point, the relationship becomes clear.
If your traffic is low, it will take longer to reach the required sample size, which means your test may need to run for several weeks. On the other hand, high-traffic stores can collect enough data much faster and reach conclusions within days.
This is why the same test can take very different amounts of time depending on the store. The difference isn’t the experiment, but it’s how quickly enough data is accumulated.
Typical Test Duration Based on Traffic
If you need a quick way to set expectations, use this as a reference:
-
Stores with low traffic (<1,000 visitors/day): Typically need around 3–4 weeks to reach reliable results
-
Stores with moderate traffic (1,000–5,000/day): Usually need about 2–3 weeks
-
Stores with high traffic (5,000+ /day): Often reach conclusions within 7–14 days
This isn’t a strict rule, but it gives you a realistic starting point based on how fast you can accumulate data.
The Trade-off: Speed vs Confidence
This is where many teams make the wrong call.
Stopping a test early can feel efficient, especially when one variant appears to be winning. But without enough data, that “winner” is often just a temporary spike. So, when you're acting on it, you're trading speed for unreliable results.
In this case, you need to wait longer until the data stabilizes, which gives you confidence that the result is real. While it slows down decision-making, it leads to better outcomes in the long run.
In A/B testing, speed feels good, but confidence is what actually drives growth.
Quick Decision Framework: When is Your Test Actually Ready
At this stage, the question is no longer about how much data you need or how long to run the test. The real question is, can you trust the result yet?
Use this as a Quick Sanity Check
If your store has low traffic, your test will naturally take longer to reach a reliable conclusion. In most cases, that means you should let your test run for several weeks before making any decisions.

With moderate traffic, you can usually expect results within a couple of weeks, as long as your sample size requirement is met and the data remains stable.
For high-traffic stores, tests can reach conclusions much faster. However, even with fast data collection, it’s still important to let the test run long enough to avoid short-term bias.
Minimum Conditions Before Calling a Winner
Before you stop any A/B test, make sure three conditions are met.
First, your test must have reached the required sample size. Without enough data, any result, no matter how strong it looks, is still unreliable.
Second, the test should have run for a sufficient period of time, typically at least one to two weeks. This ensures your data reflects real user behavior instead of short-term fluctuations.
Finally, the result should be stable. If performance keeps shifting day by day, it’s a sign that the test hasn’t fully settled yet.
The One Rule Most Teams Ignore
If you’re unsure whether to stop or continue a test, the safer decision is almost always to wait.
Stopping early can save your time, but it increases the risk of acting on incomplete data. On the other hand, waiting a bit longer allows patterns to stabilize and gives you confidence that the result is real.
And in A/B testing, confidence is what turns experiments into actual growth.
How GemX Helps You Make Better A/B testing Decisions
Knowing how much data you need and how long to run a test is only half the equation. The hardest part is knowing when to trust the results.
Because in reality, most tests don’t fail on setup. They fail at the moment of decision: when a variation looks like it’s winning, but the data isn’t actually ready.
#1. See When Results Start to Stabilize
As your test runs, performance will naturally fluctuate. Some days one variant wins, the next day it drops. This is normal, but it’s also where most wrong decisions happen.
With GemX, you can continuously track how each variation performs over time, instead of relying on a single snapshot. This makes it easier to spot whether a result is actually stabilizing or still moving.

That distinction matters more than any single uplift number.
#2. Avoid Acting on Early “Winners”
One of the most common mistakes in A/B testing is reacting too quickly to early results.
A short-term spike can look convincing, especially when the uplift seems significant. But without enough data behind it, that signal is often misleading.
GemX helps you keep experiments in context, so you’re not making decisions based on a few days of data, but on how results evolve over the full duration of the test.
#3. Turn Testing into a Repeatable System
When you combine a clear understanding of sample size, test duration, and real performance trends, A/B testing becomes much more predictable. Instead of guessing when to stop or which result to trust, you’re working with a consistent view of how your experiments behave over time.

That’s what allows you to move from running tests to actually learning from them.
Key takeaway: If you’re already running experiments but still second-guessing your results, that’s usually a sign you’re missing visibility, not effort. And that’s exactly the gap GemX is built to solve.
Common Mistakes That Lead to False Winners
By now, you know sample size and duration determine how reliable your results are. But in reality, most wrong decisions don’t come from theory, but they come from how tests are executed.
-
Stopping tests too early: A variant looks like it’s winning after a few days, so the test gets stopped. The problem is, early results are often unstable. What looks like a clear winner can easily change as more data comes in.
-
Trusting uplift without enough data: A 20% increase sounds strong, but without enough sample size, it’s just noise. Big swings are common with small datasets, which makes early results look more convincing than they actually are.
-
Testing on low-traffic pages: Low traffic means slower data collection. This often leads to tests that either run too long without clarity or get stopped too early, both resulting in unreliable outcomes.
-
Running too many variants: More variants means less traffic per variant, and this slows down data collection and makes results harder to trust.
-
Ignoring result stability: Even with enough data, results need to stabilize. If performance keeps fluctuating day by day, the test isn’t ready yet.
Learn more: 13+ A/B Testing Mistakes That Hurt Your Store Conversions
Conclusion
A/B testing may seem like a fast-paced process, involving the launch of experiments, the identification of winners, and the rapid shipping of results. But speed without enough data doesn’t lead to better decisions. It just leads to more mistakes.
Sample size tells you how much data you need, and test duration tells you how long it takes to get there. Miss either one, and even the most promising results can be misleading.
If you’re serious about running A/B tests that drive real revenue instead of just random wins, install GemX and start making decisions you can actually trust!
FAQs about Sample Size for A/B Testing




